
Year over year is an abomination of a methodology and should be banned from data analysis
Use this, it's much better

Before I get into the meat of this rant, I’d like to say that my main point is not that giving monthly numbers is incompetent, but I will get that out of the way now. There’s this ongoing deep mystery of the universe: “Why does our monthly revenue always drop in February?” It’s because it has less days in it, ya dumbass. What you should be doing is average daily numbers with months as the time intervals of measurement, and longer term stats being weighted by lengths of months. That’s still subject to some artifacts but they’re vastly smaller and hard to avoid. (Whoever decided to make days and years not line up properly should be fired.)
Even if you aren’t engaged in that bit of gross incompetence, it’s still that case that not only year over year but any fixed time interval delta is something you should never, ever use. This includes measuring historical inflation, the performance of a stock, and the price of tea in China. You may find this surprising because the vast majority of graphs you ever see present data in exactly this way, but it’s true and is a huge problem.
Let’s consider the criteria we want out of a smoothing algorithm:
There shouldn’t be any weird artifacts in how the data is presented
There should be minimal parameterization/options for p-hacking
Only the data from a fixed window should be considered
Data from the future should not be considered
So what’s wrong with straightforwardly applying even weighting across the entire time interval? The issue is that it grants a special and extreme cutoff status to two very specific points in time: Right now and the beginning of the interval. While right now is hard to do anything about (but more on that later) granting special status to an arbitrary point in the past is just wrong. For example, here’s a year over year weighted average in a scenario where there was a big spike one month, which is the most artifact-laden scenario:
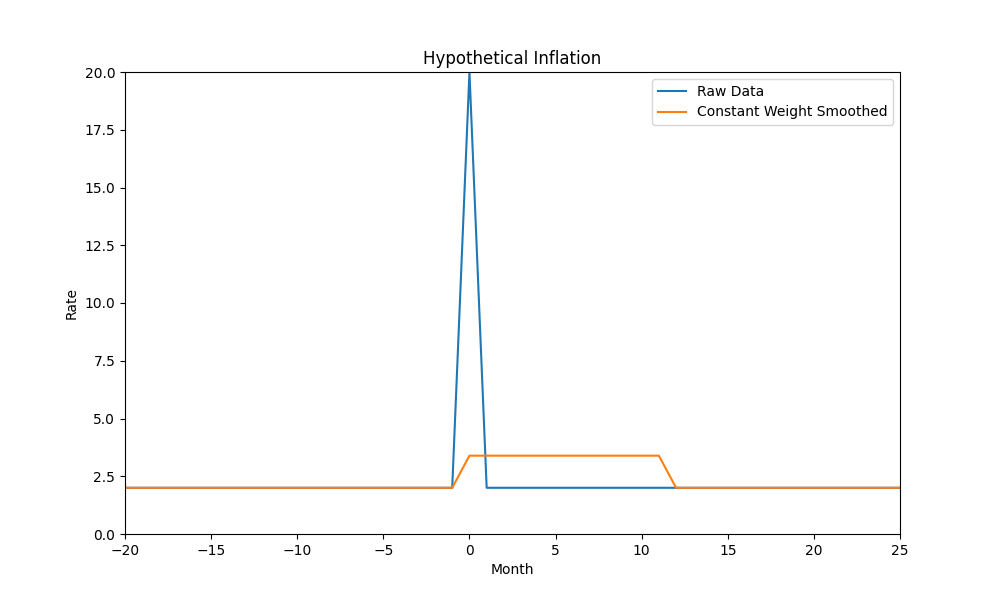
What happened exactly a year after the spike? Absolutely nothing, it’s an artifact of the smoothing algorithm used. You could argue that by picking a standard interval to use the amount of possible p-hacking is mitigated and it’s true. But the effects are still there and people can always decide to show the data at all only when the artifact goes the way they want and it’s extremely hard to standardize enough to avoid trivial p-hacks. For example it’s viewed as acceptable to show year to date, and that may hit a different convenient cutoff date.
(The graphs in this post all use weighted geometric means and for simplicity assume that all months are the same length. As I said at the top you should take into account month lengths with real world data but it’s beside the point here.)
What you should be using is linear weighted moving average, which instead of applying an even weighting to every data point has the weighting go down linearly as things go into the past, hitting zero at the beginning of the window. Because the early stuff is weighted less the size of the window is sort of narrower than with constant weighting. To get roughly apples to apples you can set it so that the amount of weight coming from the last half year is the same in either case, which corresponds to the time interval of the linear weighting being multiplied by the square root of 2, which is roughly 17 months instead of 12. Here’s what it looks like with linear weighted averages:

As you can see the LWMA doesn’t have a sudden crash at the end and much more closely models how you would experience the spike as you lived through it. There’s still some p-hacking which can be done, for example you can average over a month or a ten years instead of one year if that tells a story you prefer, but the effects of changing the time interval used are vastly less dramatic. Changing by a single month will rarely have any noticeable effect at all, while doing the same with a strict cutoff will matter fairly often.
Stock values in particular are usually shown as deviations from a single point at the beginning of a time period, which is all kinds of wrong. Much more appropriate would be to display it in the same way as inflation: annual rate of return smoothed out using LWMA over a set window. That view is much less exciting but much more informative.
In defense of the future
Now I’m going to go out on a limb and advocate for something more speculative. What I said above should be the default, what I’m about to say should be done at least sometimes, but for now it’s done hardly ever.
Of the four criteria at the top the dodgyest one by far is that you shouldn’t use data from the future. When you’re talking about the current time you don’t have much choice in the matter because you don’t know what will happen in the future, but when looking at past data it makes sense to retroactively take what happened later into account when evaluating what happened at a particular time. This is especially true of things which have measurement error, both from noise in measurement and noise in arrival time of effect. Using both before and after data simply gives better information. What it sacrifices is the criterion that you don’t retroactively change how you view past data after you give information at the time. While there’s some benefit to revisiting the drama as you experienced it at the time, that shouldn’t always be more important than accuracy.
Here’s a comparison of how a rolling linearly weighted average which uses data from the future would show things in real time versus in retrospect:

(This assumes a window of 17 months centered around the current time and data from the future elided, so the current value is across a window of 9 months.)
The after the fact smoothing is much more reasonable. It’s utilizing 20/20 hindsight, which is both its strength and weakness. The point is sometimes that’s what you want.